Introduction
At Spendesk, the biggest part of the code today is a monolith. Initially, we were using the ORM Sequelize everywhere in the code: functions were returning instances of Sequelize models, taking instances of Sequelize models as parameters, … even the HTTP controller of our app API were responding with instances of Sequelize models stringified.
It had advantages at the beginning:
- you write code faster
- you can query the database everywhere
- wrap queries on different unrelated tables in the same transaction
- fields auto generated by the ORM (ids, timestamps, …)
But with time, we increased our code quality and the design of our features. So doing this was not a good idea anymore.
Testing is really painful
If a function takes an instance of a Sequelize model or returns one, it’s painful to test. We can use Javascript plain objects as input, and test attributes of the returned values, but we don’t really test it well as it’s not the same data as in production.
But the worst part is if the function we are testing is using methods of the Sequelize model instance (getter, setter), or is querying the database. We can try to mock everything, but it’s not easy to do. The other solution is to set up a test database and use a real database while running the test suite. The test suite will be slow, but at least we can test the code.
It’s hard to type with Typescript
We now use Typescript at Spendesk. Typing a Javascript Plain Objet is simple. Typing a Sequelize model instance is really not something you want to do.
The complexity of the storage is mixed with the business logic
The entities we are using in the code are not business objets, but Sequelize model instances based on the structure of the database.
One solution to solves these problems was to use the Repository Pattern.
Quick presentation of the repository pattern
It’s a design pattern used to abstract the data layer.
In the business logic, you don’t care where data is stored or how. You just want to manipulate entities that have a real sense for your business, no matter what is used behind to store them (SQL database, NOSQL database, RAM, files, …).
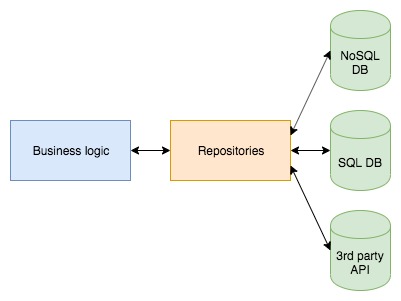
The objects manipulated and returned by the repositories are business objects that don’t depend on the storage.
Imagine a card entity, and each card has events (blocked, unblocked, ..). In the business logic we may want to represent a card as an object with an array of card events as an attribute. In a NoSQL database, we can store it like this. In a SQL database, we’ll have 2 tables with a foreign key in the card events table. The card repository will fully abstract the storage, so you won’t have any foreign keys in the card entity exposed by the repository.
Starting to use repositories in the monolith
What does it change ?
Before we started using repositories at Spendesk, the access to the database was more like this
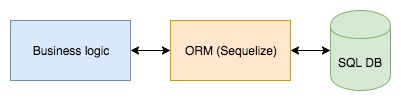
We didn’t want to stop using Sequelize, because it’s useful for other things (like database migrations) and it would have added more complexity to add a second way to access the database. The goal was to use Sequelize inside SQL database implementation of the repositories.
For new features in the monolith, here is how it looks

Building a repository
Let’s imagine a simple business entity Card that contains a list of Events where each event can be:
- the owner blocking the card
- the owner unblocking the card
- the card being activated
- the pin code sent by sms to the owner
type CardEvent = {
name: 'blocked' | 'unblocked' | 'activated' | 'pin-code-sent';
date: Date;
}
type Card = {
id: string;
owner: string;
cardNumber: string;
expiresAt: Date;
code: string;
isBlocked: boolean;
isActivated: boolean;
events: CardEvent[];
}
Now let’s define the repository’s interface. This repository will be used by a Card service that will have all the business logic of cards. So the repository’s methods are simple crud operations that take the input and read or write in the storage.
To do an update on a card, or add a new card event for example, the repository reads the card entity, makes the changes, and then calls the upsert method with the updated card.
interface CardRepository {
getById: (id: string) => Promise<Card>;
getManyById: (ids: string[]) => Promise<Card[]>;
upsert: (card: Card) => Promise<void>;
}
Now we can build a Sequelize implementation of the repository
import {
Card as CardModel,
CardEvent as CardEventModel,
} from 'path/to/sequelize/models';
export const getById = async (id: string): Promise<Card> => {
const sequelizeCard = await CardModel.find({
where: { id },
includes: [{ model: CardEventModel }],
});
const card = // reshape sequelizeCard to Card
return card;
};
export const getManyById = async (ids: string[]): Promise<Card[]> => {
// ...
};
export const update = async (card: Card): Promise<void> => {
// ...
};
So, now the problems we had are solved, right?
It’s hard to type with Typescript
The repository is fully typed.
The complexity of the storage is mixed with the business logic
The repository is dumb, all the business logic is in the card service that is using the repository.
Testing is really painful
Now, we only deal with javascript plain objects, and not with Sequelize model instances anymore.
In production, we use the Sequelize implementation. But for testing, we can use another implementation of the CardRepository, like an in-memory implementation (that uses a Map instead of a real database). This way, each database query will be replaced by a Map method call, and we don’t have to setup/clean a database during your test suite.
To use one implementation instead of the other, you can use dependency injection. Let’s say you have a Card service that is using the Card repository. In the code, when building the Card service, we’ll give it the Sequelize implementation of the Card repository as a dependency. But in the test suite, when building the Card service, we can give it the in-memory implementation fo the Card repository.
Of course, you need first to make sure that both implementations of the repository are working the same (by having a common test suite).